OpenAI o1 alternatives // reasoning [datasets] is all you need
CoT and similar techniques aren’t new and already implemented in open source/scientific community projects.
Are there great open source alternatives to new OpenAI o1 “reasoning“ models? // not yet
Actually we don’t need entirely new models for CoT/RL, but more datasets for FT/ICL. That “reasoning” is just a CoT (multi-hop LLM run) + ranking. Generation of CoT candidates and best one selection. Much more of compute is required then just single LLM execution. We need more high quality datasets with reasoning patterns.
And what about Agents? // AI Agents are more capable (tools, code, memory, etc.) for reasoning…

Marketing hype around “chain of thoughts”, LLM CoT is just a text patterns seq-to-seq generation (with errors aka hallucinations), absolutely not what humans do (we don’t know exactly).


Information seeking and integration is a complex cognitive task that consumes enormous time and effort. Search engines reshape the way of seeking information but often fail to align with complex human intentions. Inspired by the remarkable progress of Large Language Models (LLMs), recent works attempt to solve the information-seeking and integration task by combining LLMs and search engines. However, these methods still obtain unsatisfying performance due to three challenges: (1) complex requests often cannot be accurately and completely retrieved by the search engine once; (2) corresponding information to be integrated is spread over multiple web pages along with massive noise; and (3) a large number of web pages with long contents may quickly exceed the maximum context length of LLMs. Inspired by the cognitive process when humans solve these problems, we introduce MindSearch (思·索) to mimic the human minds in web information seeking and integration, which can be instantiated by a simple yet effective LLM-based multi-agent framework consisting of a WebPlanner and WebSearcher. The WebPlanner models the human mind of multi-step information seeking as a dynamic graph construction process: it decomposes the user query into atomic sub-questions as nodes in the graph and progressively extends the graph based on the search result from WebSearcher. Tasked with each sub-question, WebSearcher performs hierarchical information retrieval with search engines and collects valuable information for WebPlanner. The multi-agent design of MindSearch enables the whole framework to seek and integrate information parallelly from larger-scale (e.g., more than 300) web pages in 3 minute, which is worth 3 hours of human effort. Based on either GPT-4o or InternLM2.5–7B models, MindSearch demonstrates significant improvement in the response quality in terms of depth and breadth, on both closed-set and open-set QA problems. Besides, responses from MindSearch based on InternLM2.5–7B are preferable by humans to ChatGPT-Web (by GPT-4o) and Perplexity.ai applications, which implies that MindSearch with open-source models can already deliver a competitive solution to the proprietary AI search engine. Code and models are available at https://github.com/InternLM/MindSearch

In-Context Learning (ICL) in Large Language Models (LLM) has emerged as the dominant technique for performing natural language tasks, as it does not require updating the model parameters with gradient-based methods. ICL promises to “adapt” the LLM to perform the present task at a competitive or state-of-the-art level at a fraction of the computational cost. ICL can be augmented by incorporating the reasoning process to arrive at the final label explicitly in the prompt, a technique called Chain-of-Thought (CoT) prompting. However, recent work has found that ICL relies mostly on the retrieval of task priors and less so on “learning” to perform tasks, especially for complex subjective domains like emotion and morality, where priors ossify posterior predictions. In this work, we examine whether “enabling” reasoning also creates the same behavior in LLMs, wherein the format of CoT retrieves reasoning priors that remain relatively unchanged despite the evidence in the prompt. We find that, surprisingly, CoT indeed suffers from the same posterior collapse as ICL for larger language models. Code is avalaible at https://github.com/gchochla/cot-priors.




When writing and talking, people sometimes pause to think. Although reasoning-focused works have often framed reasoning as a method of answering questions or completing agentic tasks, reasoning is implicit in almost all written text. For example, this applies to the steps not stated between the lines of a proof or to the theory of mind underlying a conversation. In the Self-Taught Reasoner (STaR, Zelikman et al. 2022), useful thinking is learned by inferring rationales from few-shot examples in question-answering and learning from those that lead to a correct answer. This is a highly constrained setting — ideally, a language model could instead learn to infer unstated rationales in arbitrary text. We present Quiet-STaR, a generalization of STaR in which LMs learn to generate rationales at each token to explain future text, improving their predictions. We address key challenges, including 1) the computational cost of generating continuations, 2) the fact that the LM does not initially know how to generate or use internal thoughts, and 3) the need to predict beyond individual next tokens. To resolve these, we propose a tokenwise parallel sampling algorithm, using learnable tokens indicating a thought’s start and end, and an extended teacher-forcing technique. Encouragingly, generated rationales disproportionately help model difficult-to-predict tokens and improve the LM’s ability to directly answer difficult questions. In particular, after continued pretraining of an LM on a corpus of internet text with Quiet-STaR, we find zero-shot improvements on GSM8K (5.9%→10.9%) and CommonsenseQA (36.3%→47.2%) and observe a perplexity improvement of difficult tokens in natural text. Crucially, these improvements require no fine-tuning on these tasks. Quiet-STaR marks a step towards LMs that can learn to reason in a more general and scalable way

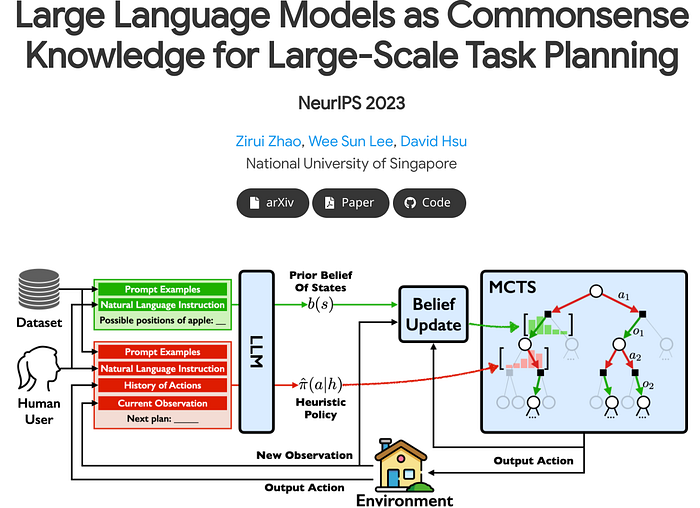
Large Language Models (LLMs) have shown remarkable capabilities in natural language tasks requiring complex reasoning, yet their application in agentic, multi-step reasoning within interactive environments remains a difficult challenge. Traditional supervised pre-training on static datasets falls short in enabling autonomous agent capabilities needed to perform complex decision-making in dynamic settings like web navigation. Previous attempts to bridge this gap through supervised fine-tuning on curated expert demonstrations often suffer from compounding errors and limited exploration data, resulting in sub-optimal policy outcomes. To overcome these challenges, we propose a framework that combines guided Monte Carlo Tree Search (MCTS) search with a self-critique mechanism and iterative fine-tuning on agent interactions using an off-policy variant of the Direct Preference Optimization (DPO) algorithm. Our method allows LLM agents to learn effectively from both successful and unsuccessful trajectories, thereby improving their generalization in complex, multi-step reasoning tasks. We validate our approach in the WebShop environment, a simulated e-commerce platform — where it consistently outperforms behavior cloning and reinforced fine-tuning baseline, and beats average human performance when equipped with the capability to do online search. In real-world booking scenarios, our methodology boosts Llama-3 70B model’s zero-shot performance from 18.6% to 81.7% success rate (a 340% relative increase) after a single day of data collection and further to 95.4% with online search. We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings.



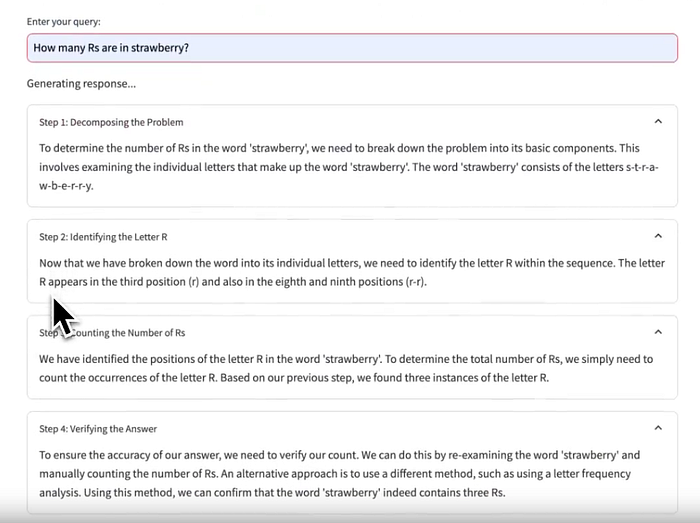
This is an early prototype of using prompting strategies to improve the LLM’s reasoning capabilities through o1-like reasoning chains. This allows the LLM to “think” and solve logical problems that usually otherwise stump leading models. Unlike o1, all the reasoning tokens are shown, and the app uses an open source model.
g1 is experimental and being open sourced to help inspire the open source community to develop new strategies to produce o1-like reasoning. This experiment helps show the power of prompting reasoning in visualized steps, not a comparison to or full replication of o1, which uses different techniques. OpenAI’s o1 is instead trained with large-scale reinforcement learning to reason using Chain of Thought, achieving state-of-the-art performance on complex PhD-level problems.
g1 demonstrates the potential of prompting alone to overcome straightforward LLM logic issues like the Strawberry problem, allowing existing open source models to benefit from dynamic reasoning chains and an improved interface for exploring them.
How it works
g1 powered by Llama3.1–70b creates reasoning chains, in principle a dynamic Chain of Thought, that allows the LLM to “think” and solve some logical problems that usually otherwise stump leading models.
At each step, the LLM can choose to continue to another reasoning step, or provide a final answer. Each step is titled and visible to the user. The system prompt also includes tips for the LLM. There is a full explanation under Prompt Breakdown, but a few examples are asking the model to “include exploration of alternative answers” and “use at least 3 methods to derive the answer”.
The reasoning ability of the LLM is therefore improved through combining Chain-of-Thought with the requirement to try multiple methods, explore alternative answers, question previous draft solutions, and consider the LLM’s limitations. This alone, without any training, is sufficient to achieve ~70% accuracy on the Strawberry problem (n=10, “How many Rs are in strawberry?”). Without prompting, Llama-3.1–70b had 0% accuracy and ChatGPT-4o had 30% accuracy.

Large Language Models (LLMs) have emerged as a groundbreaking technology with their unparalleled text generation capabilities across various applications. Nevertheless, concerns persist regarding the accuracy and appropriateness of their generated content. A contemporary methodology, self-correction, has been proposed as a remedy to these issues. Building upon this premise, this paper critically examines the role and efficacy of self-correction within LLMs, shedding light on its true potential and limitations. Central to our investigation is the notion of intrinsic self-correction, whereby an LLM attempts to correct its initial responses based solely on its inherent capabilities, without the crutch of external feedback. In the context of reasoning, our research indicates that LLMs struggle to selfcorrect their responses without external feedback, and at times, their performance even degrades after self-correction. Drawing from these insights, we offer suggestions for future research and practical applications in this field.

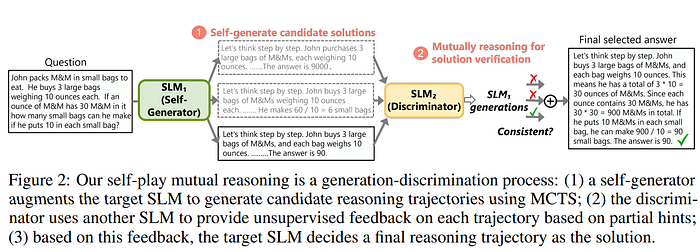
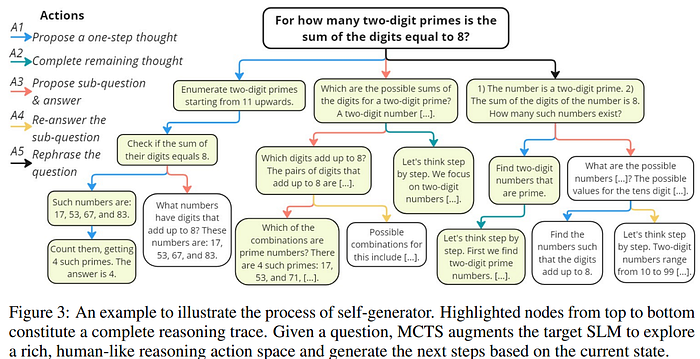
This paper introduces rStar, a self-play mutual reasoning approach that significantly improves reasoning capabilities of small language models (SLMs) without finetuning or superior models. rStar decouples reasoning into a self-play mutual generation-discrimination process. First, a target SLM augments the Monte Carlo Tree Search (MCTS) with a rich set of human-like reasoning actions to construct higher quality reasoning trajectories. Next, another SLM, with capabilities similar to the target SLM, acts as a discriminator to verify each trajectory generated by the target SLM. The mutually agreed reasoning trajectories are considered mutual consistent, thus are more likely to be correct. Extensive experiments across five SLMs demonstrate rStar can effectively solve diverse reasoning problems, including GSM8K, GSM-Hard, MATH, SVAMP, and StrategyQA. Remarkably, rStar boosts GSM8K accuracy from 12.51% to 63.91% for LLaMA2–7B, from 36.46% to 81.88% for Mistral-7B, from 74.53% to 91.13% for LLaMA3–8BInstruct. Code will be available at here.
Reasoning and beyond tests
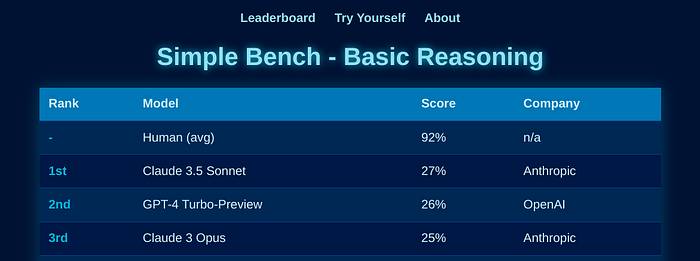
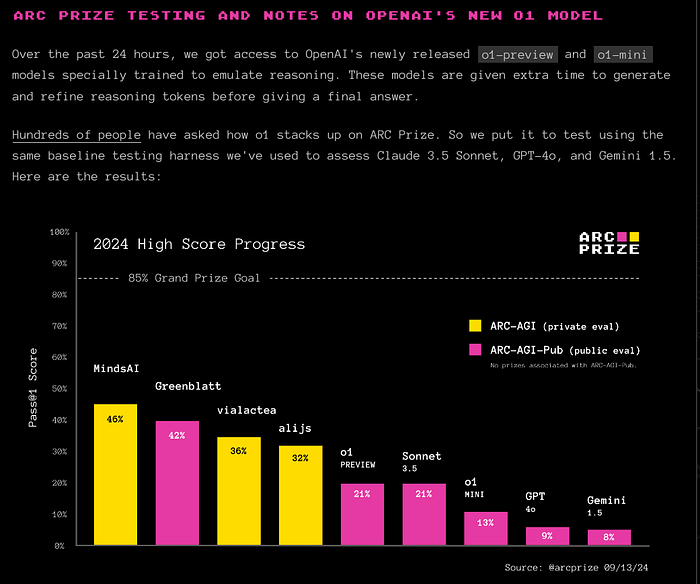

The Abstraction and Reasoning Corpus (ARC) is a visual program synthesis benchmark designed to test challenging out-of-distribution generalization in humans and machines. Since 2019, limited progress has been observed on the challenge using existing artificial intelligence methods. Comparing human and machine performance is important for the validity of the benchmark. While previous work explored how well humans can solve tasks from the ARC benchmark, they either did so using only a subset of tasks from the original dataset, or from variants of ARC, and therefore only provided a tentative estimate of human performance. In this work, we obtain a more robust estimate of human performance by evaluating 1729 humans on the full set of 400 training and 400 evaluation tasks from the original ARC problem set. We estimate that average human performance lies between 73.3% and 77.2% correct with a reported empirical average of 76.2% on the training set, and between 55.9% and 68.9% correct with a reported empirical average of 64.2% on the public evaluation set. However, we also find that 790 out of the 800 tasks were solvable by at least one person in three attempts, suggesting that the vast majority of the publicly available ARC tasks are in principle solvable by typical crowd-workers recruited over the internet. Notably, while these numbers are slightly lower than earlier estimates, human performance still greatly exceeds current state-of-the-art approaches for solving ARC. To facilitate research on ARC, we publicly release our dataset, called H-ARC (human-ARC), which includes all of the submissions and action traces from human participants.1

We introduce Diagram of Thought (DoT), a framework that models iterative reasoning in large language models (LLMs) as the construction of a directed acyclic graph (DAG) within a single model. Unlike traditional approaches that represent reasoning as linear chains or trees, DoT organizes propositions, critiques, refinements, and verifications into a cohesive DAG structure, allowing the model to explore complex reasoning pathways while maintaining logical consistency. Each node in the diagram corresponds to a proposition that has been proposed, critiqued, refined, or verified, enabling the LLM to iteratively improve its reasoning through natural language feedback. By leveraging auto-regressive next-token prediction with role-specific tokens, DoT facilitates seamless transitions between proposing ideas and critically evaluating them, providing richer feedback than binary signals. Furthermore, we formalize the DoT framework using Topos Theory, providing a mathematical foundation that ensures logical consistency and soundness in the reasoning process. This approach enhances both the training and inference processes within a single LLM, eliminating the need for multiple models or external control mechanisms. DoT offers a conceptual framework for designing next-generation reasoning-specialized models, emphasizing training efficiency, robust reasoning capabilities, and theoretical grounding1 .
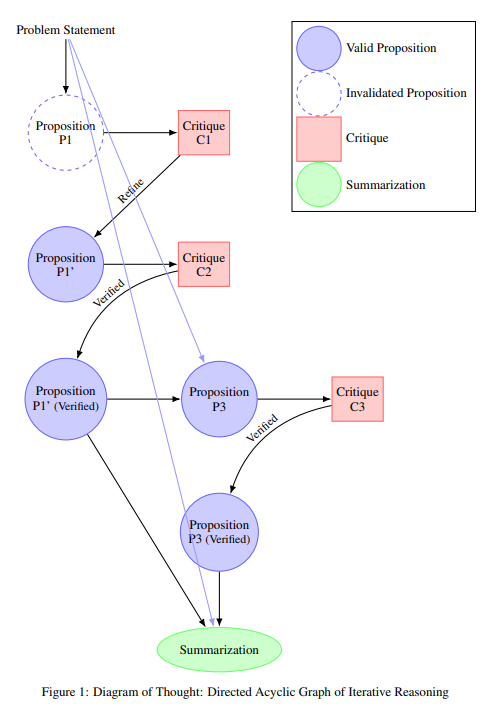
In this paper, we presented the Diagram of Thought (DoT) framework, which models iterative reasoning in large language models as the construction of a directed acyclic graph within a single LLM. By integrating propositions, critiques, refinements, and verifications into a unified DAG structure, DoT captures the complexities of logical deduction beyond linear or tree-based models. The framework leverages auto-regressive next-token prediction with role-specific tokens to manage role transitions seamlessly, enabling the model to generate detailed reasoning processes without external intervention. We further provided a topos-theoretic formalization of the DoT framework, offering a mathematical foundation that clarifies the relationship between the reasoning processes and categorical logic. By representing propositions, inferences, and critiques within the structures of a topos, we ensured logical consistency and soundness in the reasoning process. This theoretical grounding validates the efficacy of DoT in enhancing the reasoning capabilities of large language models and bridges the gap between practical implementation and mathematical rigor

xRx is a framework for building AI-powered reasoning systems that interact with users across multiple modalities, where “x” represents the flexible integration of text, voice, and other interaction forms.
We believe that the future of software interactions lies in multimodal experiences, and xRx is at the forefront of this movement. It enables developers to build sophisticated AI systems that seamlessly integrate various input and output modalities, providing users with a truly immersive experience.
